시맨틱 캐시
[시맨틱캐시 AI 『요즘 당근 AI』라는 책에서 눈여겨 내용은 여러개가 있는데 그 중 하나가 ‘시맨틱 캐시’ 의 적용이다. 오늘은 이 내용을 정리해 보려고 한다.
당근 앱에서는 채팅에서 ‘AI추천 메시지’라는 기능이 있다.
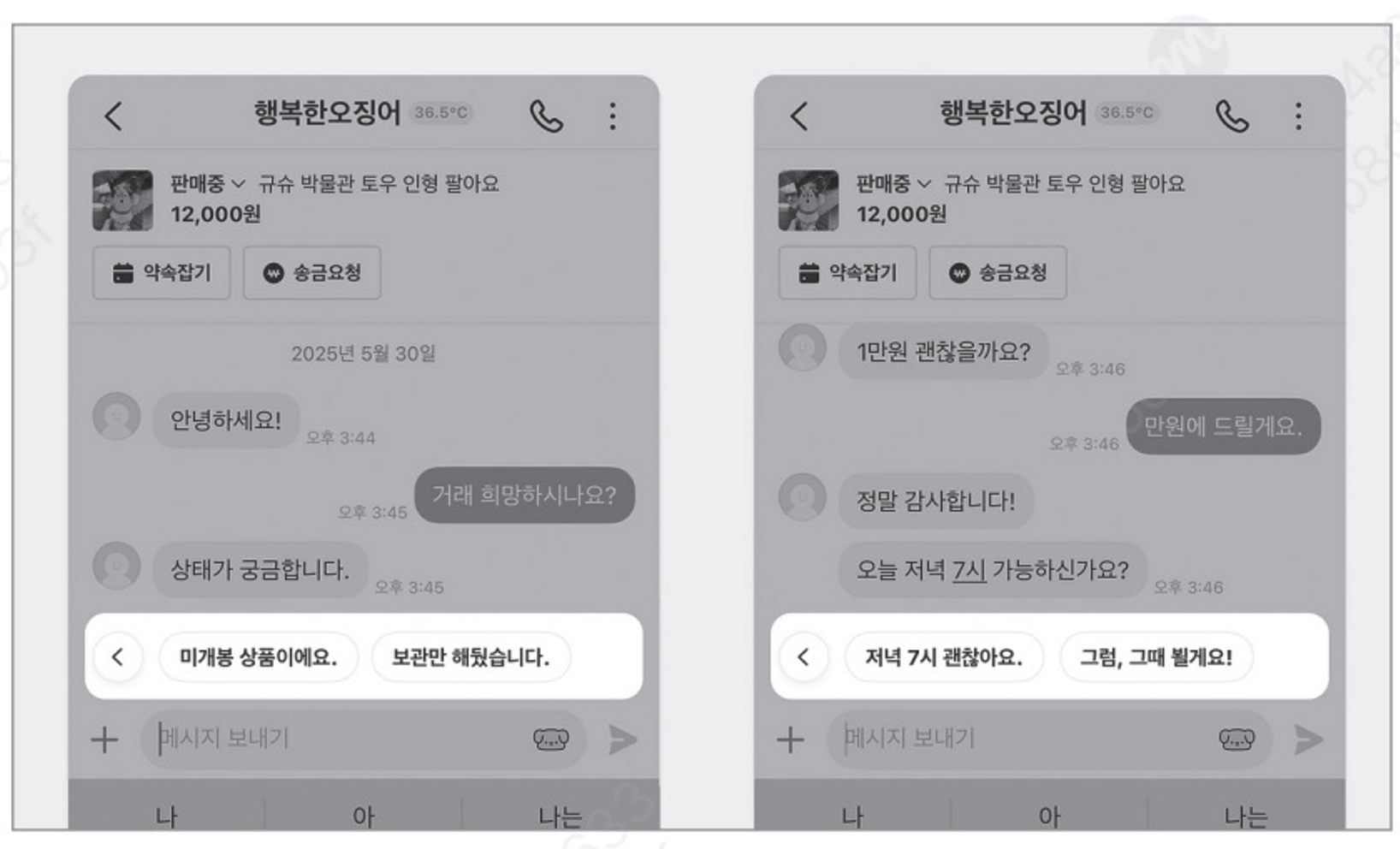
이전에는 마지막 메시지를 LLM에 던져 추천 문장을 받았다고 한다. 이렇게 되면 두 가지 문제가 발생을 하는데
- LLM의 응답을 기다려야 하는 점(속도가 느리다)
- LLM 사용 토큰 비용
특히 토큰 비용을 추정을 해 보았는데, 당근 시스템에서는 1년에 약 1000만건의 메시지가 오고가고 있고 이를 위한 추천 토큰 비용을 추정해 보니 약 8억 ~ 9억원 정도에 달한다고 한다.
이 문제점들을 완화하기 위해 당근에서 생각했던 것이 바로 “시맨틱 캐시(Symantic cache)” 라는 것이다.
추천 문장들을 캐싱해 놓고 LLM으로 던지기 전에 캐시를 먼저 뒤져서 캐시에 히트하면 그 결과로 보여주는 개념이다.

시맨틱 캐싱의 기본 원리는 매칭 기준을 ‘유사도’로 판단한다는 것이다. 이를 위해 시맨틱 캐싱에 사용되는 저장소는 벡터DB를 사용한다. 글쓴이는 chromem_go 를 메모리에 올려 사용했지만, 벡터 DB중 온메모리로 사용가능한 것이면 어떤것이든 상관없다.
캐싱 구조라면 1번 속도 문제 해결에는 도움이 될 것 같다. 그럼 2번 비용 문제는 얼마나 도움이 될 까?
당근 앱에서 오가는 채팅 메시지가 약 1000만건 정도 된다고 한다. 캐싱 미사용시 하루에 들어가는 사용 비용은
9억원(연간LLM예상 비용) ÷ 365일 = 2,465,000원
캐싱을 사용하고 캐시 히트가 100%라고 가정을 하면 들어가는 비용은… 1400원 정도로 예측을 했다.

시스템에서 현실적으로 ‘캐시히트 100%’ 가 나오기는 힘들다. 캐시 히트율을 기반으로 개략적인 비용을 계산해 보니 다음과 같았다고 한다.
| 캐시 히트율 | 비용 감소율 | 연간 비용 절감분 | 적용 후 예상 비용 |
|---|---|---|---|
| 25% | 24%절감 | 2.16억 원 | 6.84억 원 |
| 50% | 48%절감 | 4.32억 원 | 4.68억 원 |
| 75% | 72%절감 | 6.48억 원 | 2.52억 원 |
시맨틱 캐시 구성은 다음과 같이 했다.

메인 서버와는 분리된 애드온(Add On)형태이며 통신은 gRPC를 썼다고 한다.
벡터DB에 문장 1000개를 저장해도 메모리는 6MB에 불과하며 이에 대한 전수 탐색시 평균 2㎳내였다. 성능면에서는 나쁘지 않지만 임베딩 생성과정에서 여전히 병목이 발생했다고 한다.
- 평균 400~800㎳
- 이에 대응하기 위해 k8s에서 리플리카를 만들어 수평 확장 전략 사용
- 리플리카가 초당 100~120 건을 처리하며 어느 정도 속도가 올라감
임베딩 모델 서비스에서도 문제가 있었다. 하나의 문장이 1500여개의 고차원 벡터로 표현되는 경우가 있는데, 이는 임베딩 과정에서 병목을 만들었다.
이의 해결을 위해 이 팀에서는 ‘주성분 분석’ 이라는 차원 축소 기법을 활용해 1500개의 차원을 50여개로 줄여 이를 해결하였다.
그 외 어려운 점은 벡터 간의 분포 클러스터링 시 보통 K-means가 많이 사용되고 있는데, 이 캐싱 시스템에서는 k값을 미리 알 수가 없기 때문에 적용하기는 어려웠다는 것이다. 그래서 이 팀은 DBSCAN 기법을 선택했다. 군집의 갯수를 미리 알 수가 없기 때문이며, 노이즈에 강하다는 장점도 있다.
이 서비스의 성과는 어떻게 될 까?
팀에서는 먼저 유사도의 기준을 잡았다. 샘플링으로 거래 대화 50개 중 1000개의 발화를 추출해 유사도 임계값을 변경해 가면서 히트 비율을 조사하였는데. 당연히 임계값이 낮을 수록 히트율은 상승했다. 임계값을 0.65로 잡았을때 히트율이 29.55% 정도였고 이 값이 가장 합리적인 것으로 판단했다.
이를 실제 사용자들에게 테스트 배포를 하고 캐시 히트율을 조사했다. 애초 20%정도를 예상했는데 결과는 25% 에 가깝게 나왔다. 그리고 일부 경우에서는 시맨틱 캐싱이 문맥을 이해하지 못해 혼란을 주는 경우도 발생했다.
표 ‘히트율에 따른 비용절감 효과’ 를 보면 25%일때 약 2.16억원의 절약이 예상된다. 결국 이 서비스의 비용적인 성과는 2.16억원이 될 것이다.
LLM을 직접 쓰기보다 시맨틱 캐시를 들이는 것은 분명 비용적으로나 속도면으로나 이익이 된다. 하지만 유사 후보 추천에서 일부 문맥을 이해하지 못한 부분은 이 팀에서 개선해야 할 숙제인것 같다.