Hadoop의 개요 설명
[Hadoop 하둡 하둡(Hadoop)의 개념을 너무 모르는 교육생들이 있어 이를 위해 정리를 여기에 해 본다.
1. Hadoop의 개념
하둡은 DFS(Distributed File System)이다. 대용량의 파일을 여러개로 쪼개어 분리된 파일 시스템에 저장하는 것이다.
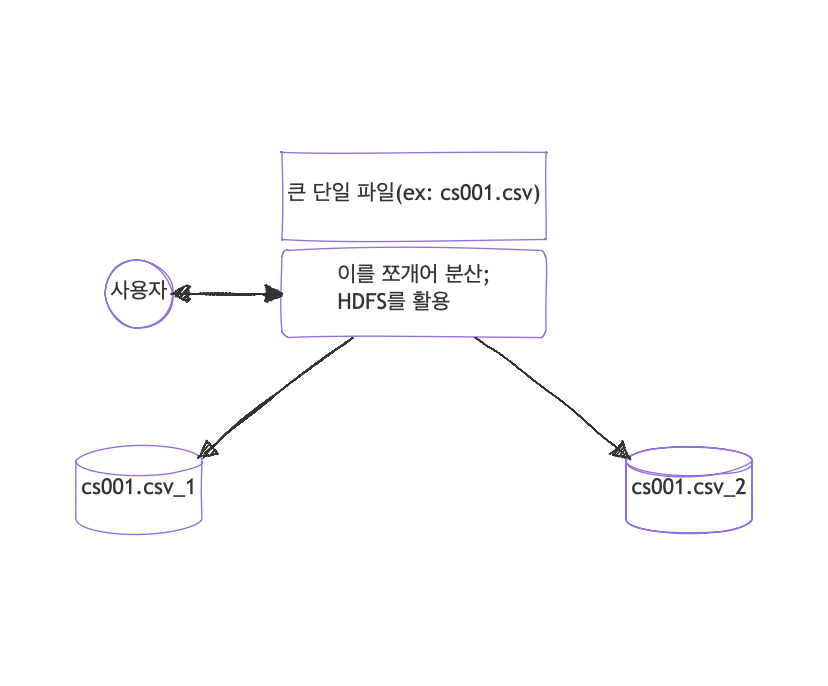
저장되는 것은 결국 csv같은 ‘파일’ 이며 사용자는 쪼개진 파일이라도 하둡을 통해 단일 파일처럼 작업을 할 수 있다.
보통 파일을 읽어들이는 것은 많은 시간이 걸린다. 그래서 일단 파일을 전부 저장해 놓고 필요한 파일을 꺼내어 RDBMS에 저장하고 이를 활용한다.
2. 사용자가 HDFS를 활용하는 여러가지 방법
2.1 HDFS기본 명령
2.1.1 HDFS에서 파일 확인
hdfs dfs -ls /user/hadoop/input
2.1.2 파일을 로컬로 복사
hdfs dfs -get /user/hadoop/input/file.txt /local/directory/
2.2 Apache Hive 로 가져오기
Hive 는 SQL과 유사한 HQL(Hive Query Language)를 사용하여 쿼리를 할 수 있다.
-- HiveQL을 사용한 데이터 쿼리
CREATE EXTERNAL TABLE my_table (field1 INT, field2 STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION '/user/hadoop/input/';
SELECT * FROM my_table;
2.3 Apache Spark 를 사용하여 가져오기
Apache Spark는 Hadoop 클러스터와 연동하여 데이터를 처리할 수 있으며, HDFS에서 데이터를 로드하여 메모리에서 빠르게 처리할 수 있다.
아래는 PySpark를 사용하여 읽는 예제이다.
from pyspark.sql import SparkSession
# Spark 세션 생성
spark = SparkSession.builder.appName("HDFS Data Load").getOrCreate()
# HDFS 파일 읽기
df = spark.read.text("hdfs://namenode:9000/user/hadoop/input/file.txt")
# 데이터 처리
df.show()
2.4 MapReduce를 사용하여 가져오기
Hadoop의 기본적인 데이터 처리 방식인 MapReduce를 활용한다.
// Mapper 클래스
public class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] fields = line.split(",");
String field1 = fields[0];
context.write(new Text(field1), new IntWritable(1));
}
}
// Driver 클래스
public class MyJob {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "HDFS Data Job");
job.setJarByClass(MyJob.class);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job, new Path("/user/hadoop/input/"));
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileOutputFormat.setOutputPath(job, new Path("/user/hadoop/output/"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
2.5 Sqoop를 사용하여 RDBMS에서 HDFS로 데이터 교환
Sqoop은 RDBMS에서 HDFS사이에 데이터 교환을 지원하는 도구이다
- DB to HDFS
sqoop import --connect jdbc:mysql://database_server/dbname --username user --password pass --table table_name --target-dir /user/hadoop/output/
- HDFS to DB
sqoop export --connect jdbc:mysql://database_server/dbname --username user --password pass --table table_name --export-dir /user/hadoop/output/
2.6 Hadoop Streaming 을 사용한 데이터 가져오기
hadoop에서 지원하는 스트리밍을 사용해 데이터를 가져올 수 있다.
hadoop jar /usr/local/hadoop/share/hadoop/tools/lib/hadoop-streaming-*.jar \
-input /user/hadoop/input/ \
-output /user/hadoop/output/ \
-mapper /path/to/mapper.py \
-reducer /path/to/reducer.py
보통 단독으로 쓰기 보다는 Spark, 또는 Hive와 연동하여 많이 사용을 하는 것 같다.