워크플로우... DIFY
[dify LLM workflow “별도의 코딩 작업 없이 RAG 검색 작업을 할 수 없을 까?”
(RAG(Retrieval-Augmented Generation)는 대규모 언어 모델의 출력을 최적화하여 응답을 생성하기 전에 학습 데이터 소스 외부의 신뢰할 수 있는 지식 베이스를 참조하도록 하는 프로세스를 의미한다)
이를 위해 사람들이 많이 고민한 결과들이 있고 그 중 하나가 dify이다.
이와 비슷한 역할을 하는 것에는 Langchain(랭체인) 이 있는데 일단 dify처럼 gui베이스가 아닌 파이썬 코딩이 필요한 인터페이스여서 접근하기에는 허들이 상당히 높다.
dify를 실행하는 방법은 여러가지가 있다. 만일 여러분들이 2CPU 에 4GB이상의 메모리를 가진 서버나 PC가 없다면 호스팅 서비스인 https://cloud.dify.ai/에 가입을 해서 설정을 하고 써 볼 수 있다. 무료 플랜부터 엔터프라이즈까지 요금제가 있으니 맞게 설정하여 쓰면 될 것이다.
2CPU 및 4GB이상의 메모리를 가진 서버가 있다면, 여러분은 여기에 설치를 하여 써 볼 수 있다. 설치는 docker 컨테이너로 설치를 지원하며 여기서는 이 방법을 선택했다. 여러분들이 docker-compose와 git에 익숙하다는 것을 전제로 한다.
먼저 git으로 dify의 레포를 clone한다.
git clone https://github.com/langgenius/dify.git
다운받는 폴더 내 ./docker 폴더로 가면 .env.example 파일이 있을 것이다. 이를 .env로 이름을 바꾼다
cd dify/docker
cp .env.example .env
.env파일을 보면 컨테이너를 띄울때 사용할 포트들을 설정할 수 있다. 적절한 포트로 설정한다. 여기서는 8001을 사용했다.
...
# ------------------------------
# Docker Compose Service Expose Host Port Configurations
# ------------------------------
EXPOSE_NGINX_PORT=8001
EXPOSE_NGINX_SSL_PORT=443
...
그 후 다음을 실행한다
docker-compose up -d
설치에 성공하면 http://localhost/install 사이트로 접속을 할 수 있다. 여기에 사용자 등록을 비밀번호와 함께 하면 호스팅 서비스와 동일한 화면이 보일 것이다.
이제 RAG 검색 플로우를 만들어 보겠다. 여기서 만들 것은 RAG의 베이스로 구글 검색 결과를 사용할 것이다. 빈 상태로 시작을 하고 $\rightarrow$ 워크플로우를 선택한다
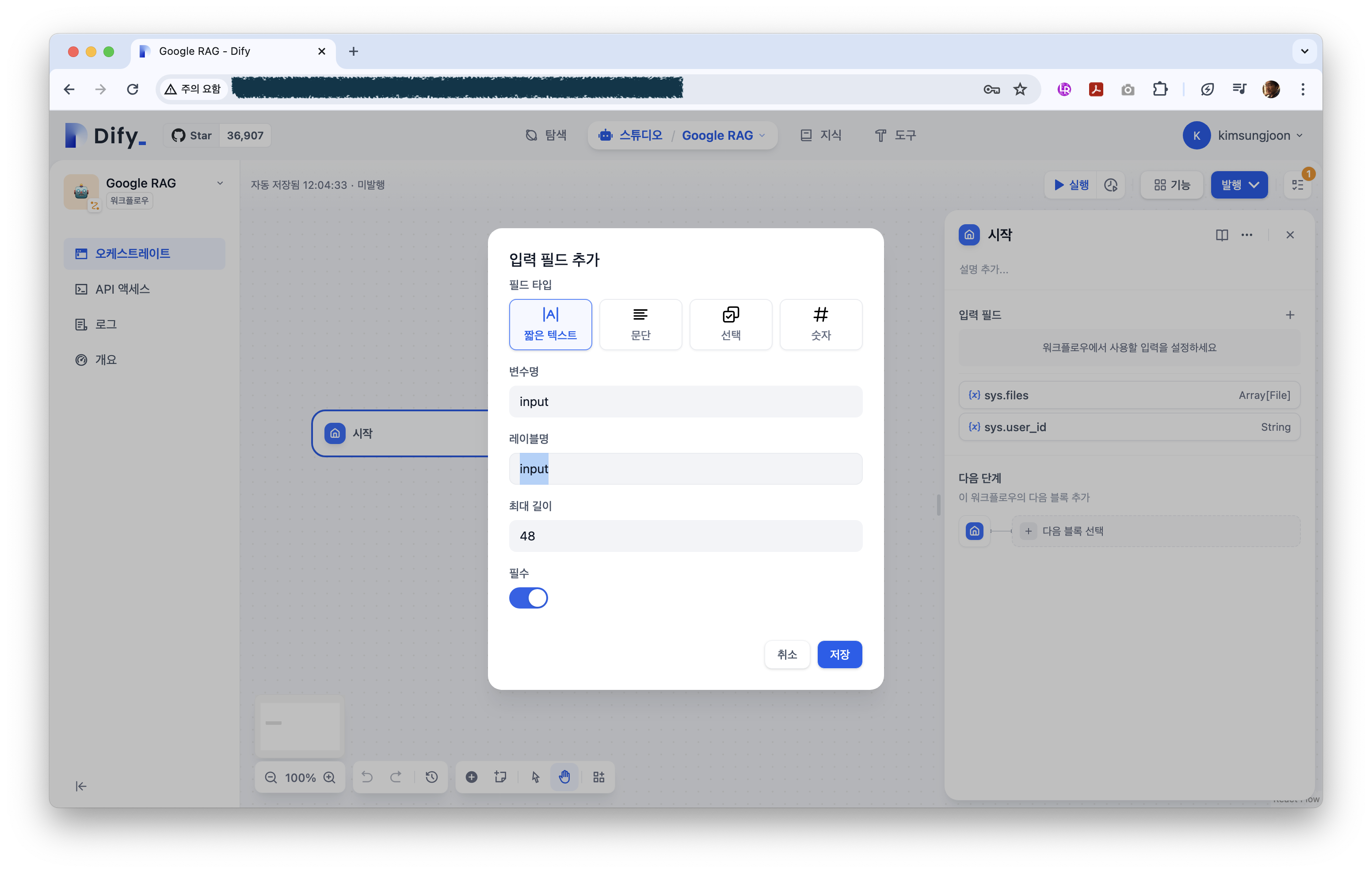
시작 포인트가 만들어지면 이제 input 을 설정해 준다.
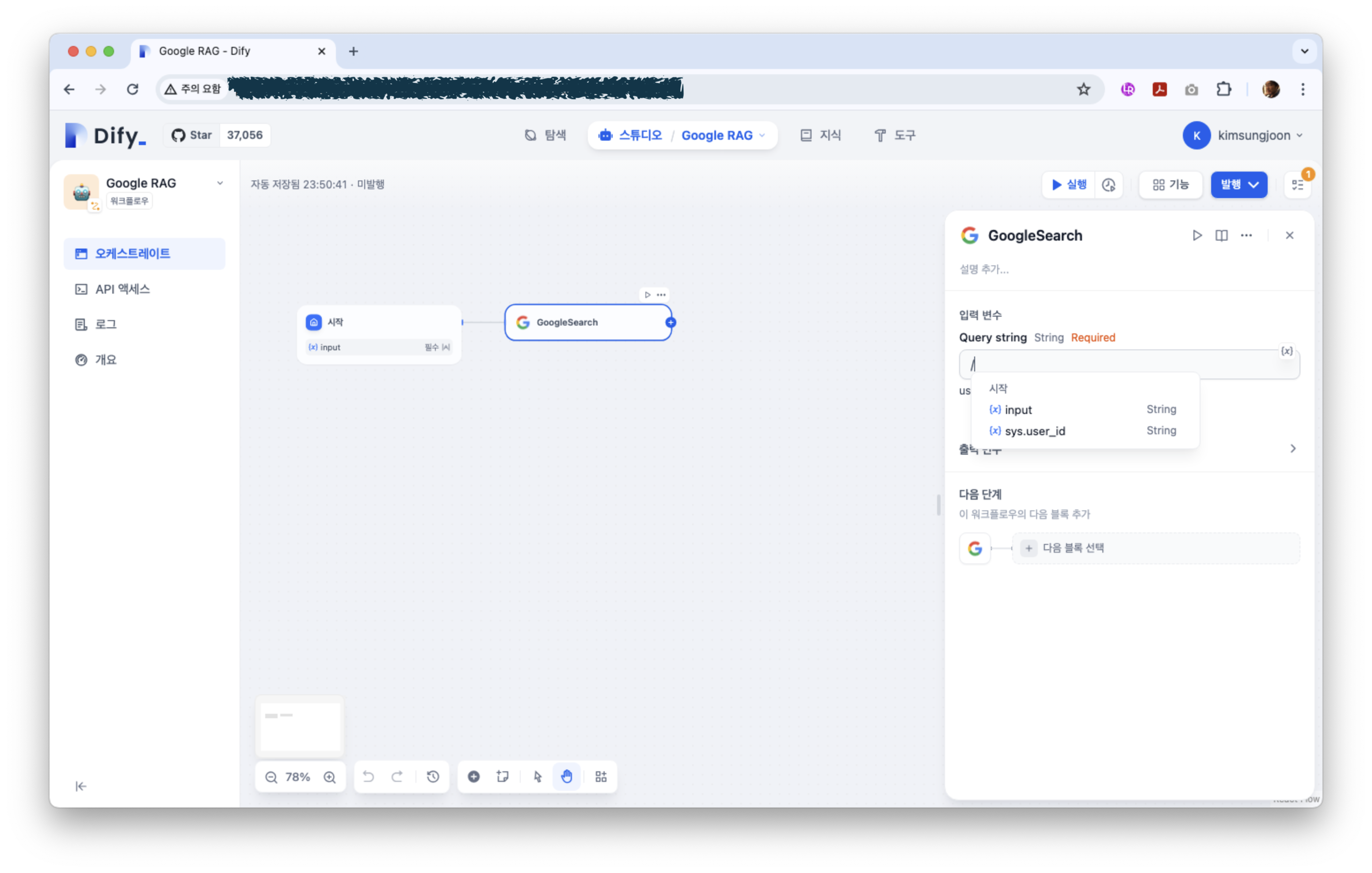
‘시작’ 다음 작업의 추가는 시작 옆의 ‘+’ 를 클릭하면 된다. 우리는 먼저 구글 검색을 할 것이라 ‘도구’ 탭의 ‘GoogleSearch’를 선택한다.
GoogleSearch를 쓰기 위해서는 Serpapi의 등록이 필요하다. 이를 등록하면 API 키를 받을 수 있고 GoogleSearch에 등록해 주어야 한다.(무료: 월 100건 제한)
GoogleSearch의 입력을 ‘시작’에서의 input으로 설정하고 그 다음단계를 설정한다.
GoogleSearch의 결과는 json 오브젝트로 반환된다(왜인지 모르겠지만 text반환이 안된다). 하지만 LLM에서는 json 오브젝트가 아닌 텍스트로 받는다. 따라서 json오브젝트를 텍스트로 변환하는 작업이 필요한데 이것이 ‘템플릿’ 이다.
아래는 템플릿의 셋팅화면이다. GoogleSearch의 json 을 선택한다.
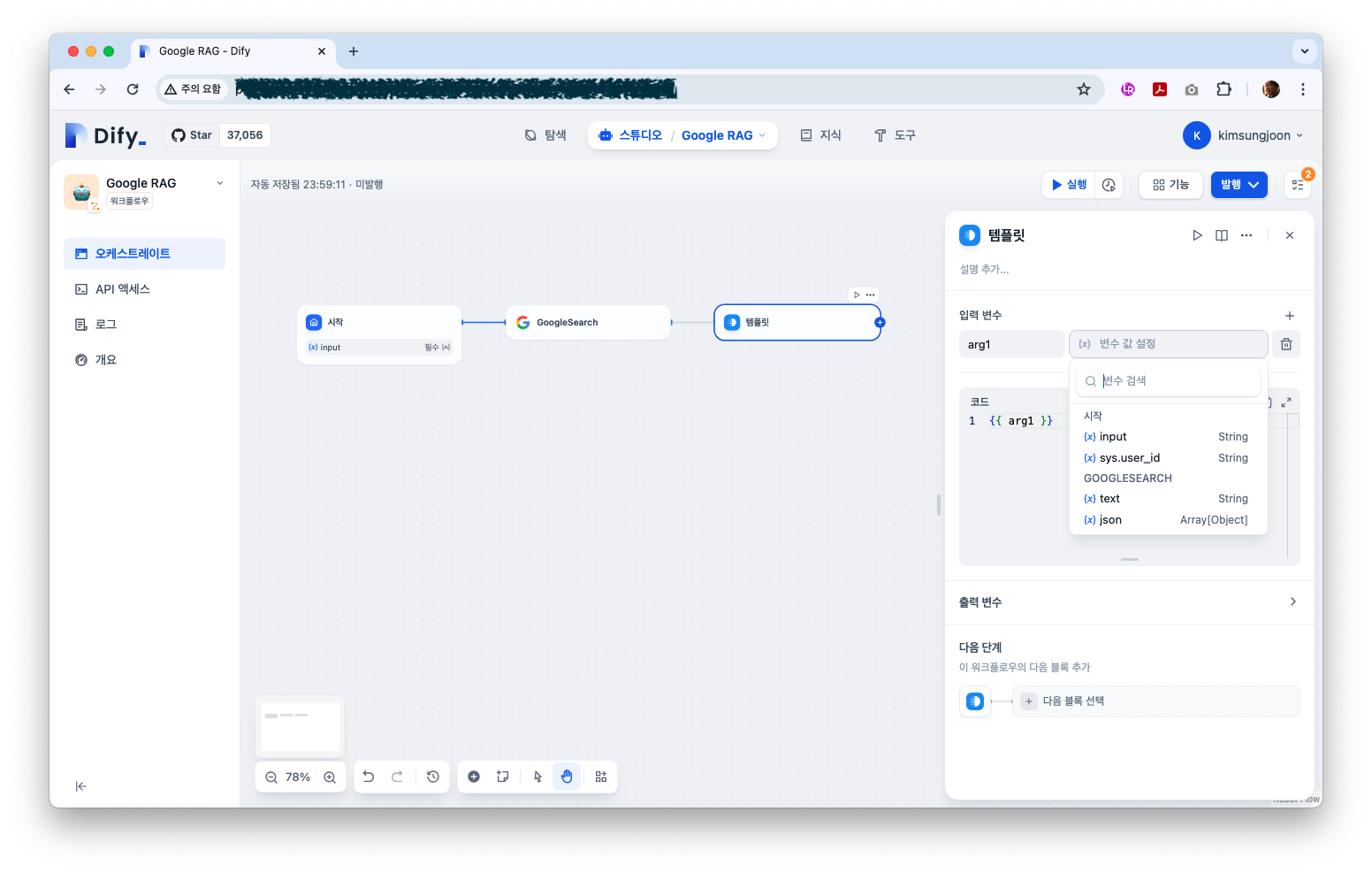
다음은 LLM연결이다. openai의 gpt api key가 필요하다. 다음 태스크로 연결하고 SYSTEM 섹션에 gpt에 던질 프롬프트를 입력한다.
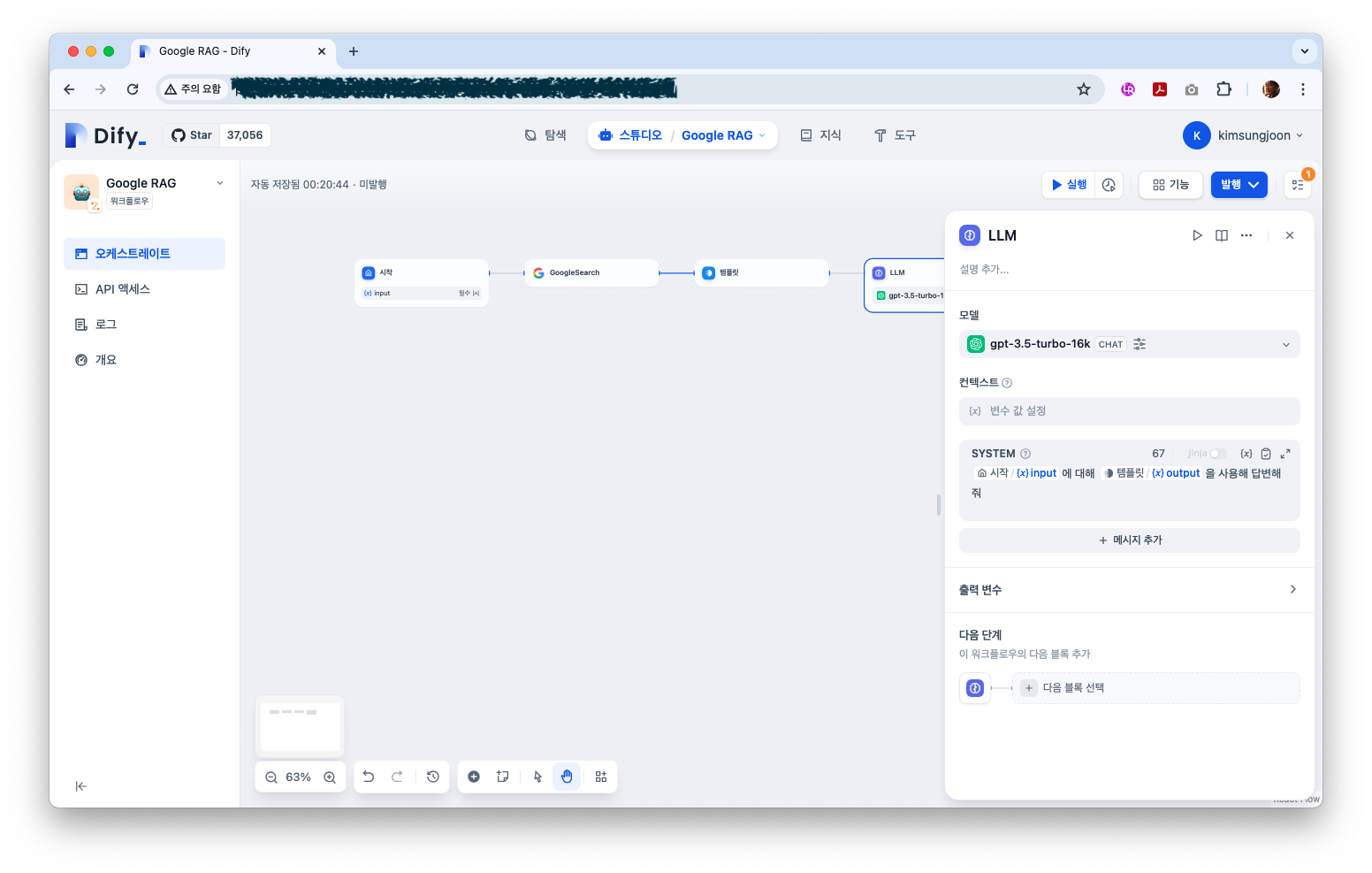
참고로 프롬프트에서는 ‘/’ 을 입력하면 각 단계에서 사용된 파라미터를 선택해 사용할 수 있다.
LLM의 처리 결과는 마지막 단계인 ‘끝’ 작업에서 출력을 한다. 출력변수는 LLM의 text를 선택한다.
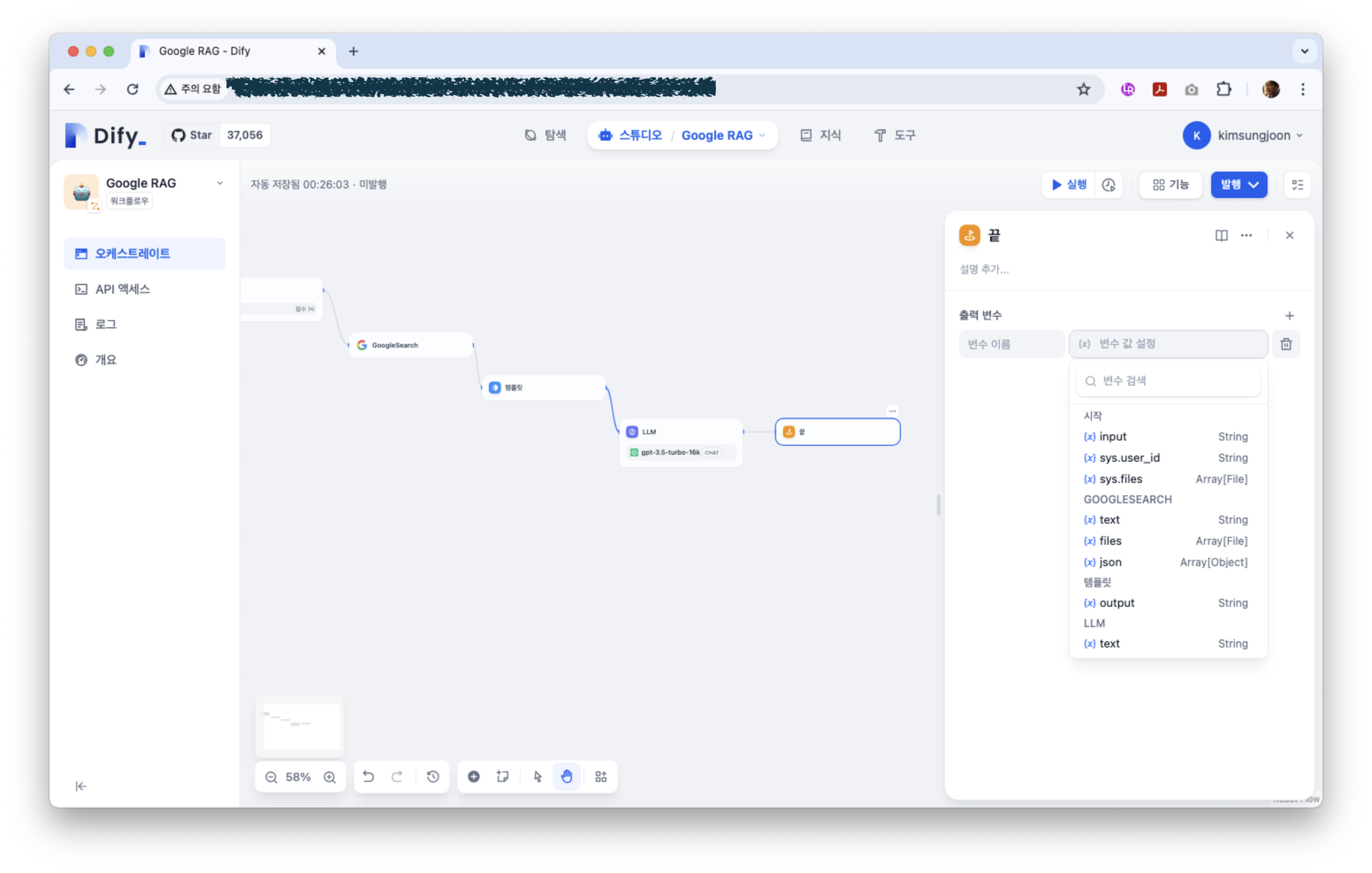
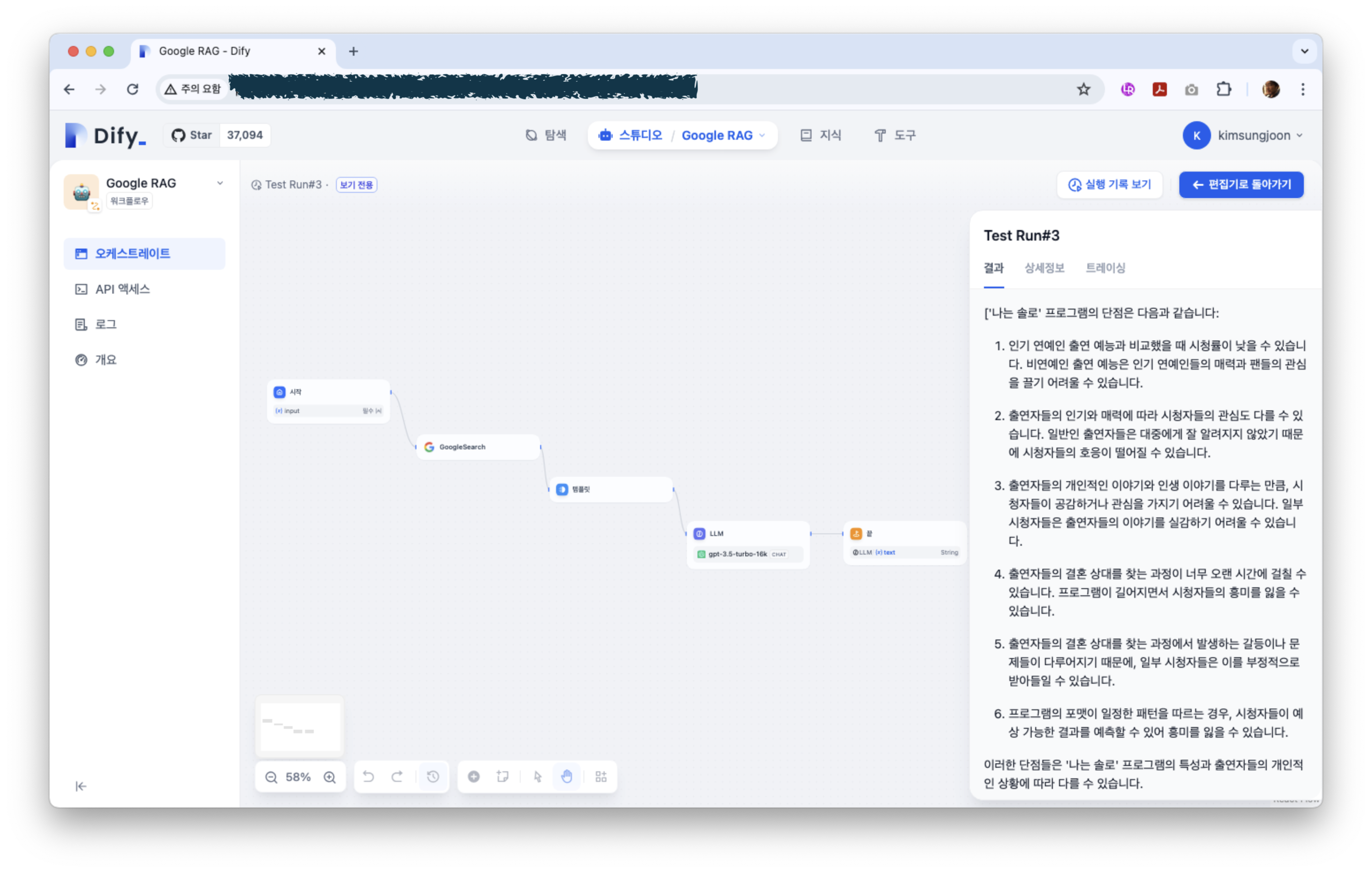
설정은 이제 완료되었다. 한번 테스트를 해 보도록 하자.
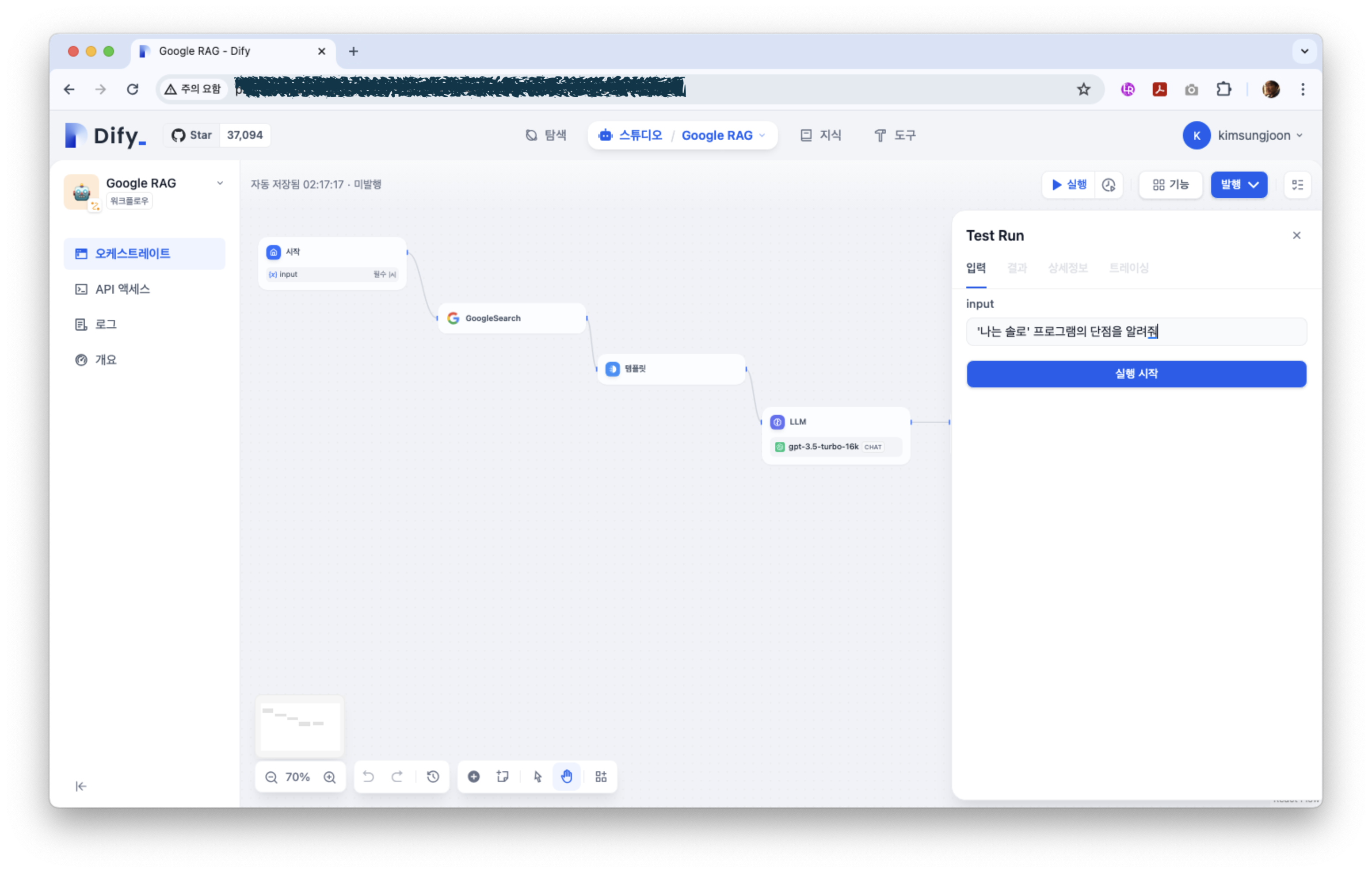
결과이다. GPT3.5를 단독으로 적용한 것보다 할루시네이션이 많이 줄어든 것을 알 수 있다.
이를 실제로 활용하기 위해서는 ‘발행’ 을 하면 되는데, API Access를 위한 base URL 및 실행을 위한 URL 들의 사용법들이 ‘API 엑세스’ 에 안내가 되어 있으니 참조하기 바란다.
참고로 Dify와 랭체인(LangChain)을 비교해 보면 다음과 같다.
| 특징 | 랭체인(LangChain) | Dify |
|---|---|---|
| 목적 | NLP 파이프라인 구성 및 모델 학습 | 데이터 분석 및 시각화 |
| 주요 기능 | 데이터 전처리, 모델 학습, 평가 등 | 다양한 데이터 소스 통합, 시각화, 협업 |
| 사용자 대상 | NLP 연구자, 데이터 과학자 | 데이터 분석가, 비즈니스 인텔리전스 전문가 |
| 확장성 | 새로운 모델과 데이터셋 추가 용이 | 다양한 데이터 소스와의 통합 용이 |
| 사용 편의성 | 코드 작성 필요 | 코드 없이도 사용 가능한 GUI 제공 |
| 협업 기능 | 없음 | 팀원과의 협업 및 공유 기능 제공 |