데이터 예측 기법 (1) - Naïve Beysian + Laplace estimator
[DataMining BigData 요새 빅데이터 및 데이터 마이닝에 심취해 있다. 내용 정리를 할 겸 공부한 내용을 여기에 기록해 본다.
날씨와 크리켓 게임의 상관관계를 조사한 데이터가 아래와 같이 있다고 생각해 보자. play는 크리켓 게임 수행 여부를 의미한다.
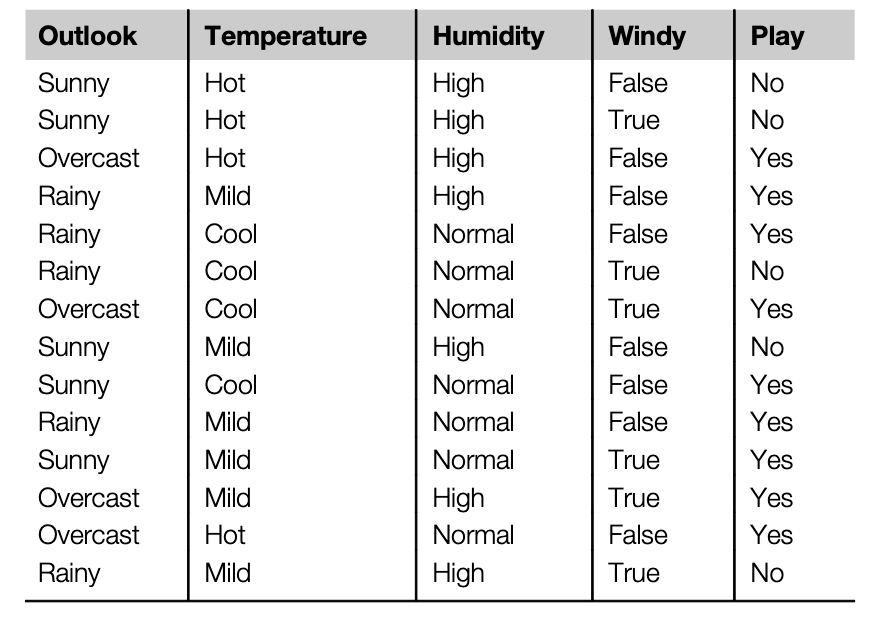
Temperature와 Humidity가 각각 Hot/Mild/Cood, High/normal 로 러프하게 주어져 있는 데이터이다.
이를 기반으로 아래 데이터의 경우 play 가능 여부를 판단하는게 목표이다.

이를 단순 확률 모델링으로 접근해 보자.
각 팩터별로 발생횟수와 확률을 계산해 보면
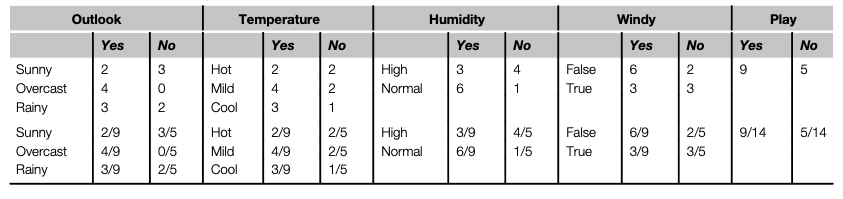
상부는 Yes, No 별 발생 횟수, 하부는 전체 횟수분에 각 팩터별 발생 확률을 나타낸다. 마지막 컬럼 play는 주어진 전체 데이터에서 Yes, No 별 발생횟수 및 확률을 구한 것이다.
방법은 간단하다. 판별하려는 데이터의 경우를 위 표에서 확률을 찾아 모두 곱하면 된다.
- Outlook 이 Sunny인 경우 : 2/9
- Temperature가 Cool인 경우 : 3/9
- Humidity가 High인 경우 : 3/9
- Windy가 True인 경우 : 3/9
- Play가 Yes : 9/14
Yes 발생 가능성은 아래와 같다.
Likelyhood of Yes = 2/9 × 3/9 × 3/9 × 3/9 × 9/14 = 0.0053
Likelyhood of No = 3/5 × 1/5 × 4/5 × 3/5 × 5/14 = 0.0206
이를 %으로 나타내어 보면
Yes의 확률 = = 20.5%
No의 확률 = = 79.5%
그러므로 위의 경우는 play=No 가 나올 가능성이 더 많다고 예측할 수 있다. 1
그러나 이 방법은 한 가지 문제점을 안고 있는데, 예측하려는 조건이 Outlook이 overcast일 경우 play는 항상 Yes이며(0건) Likelyhood of No 는 아무리 다른 팩터의 확률이 크다 하더라도 전부 무시되고 0이 되어 버린다. 이는 상당히 부적절하지 아니한가…!
어차피 확률은 비율의 문제이기 때문에 분자, 분모에 적절한 보정 값을 추가해 줘도 문제는 없을 것 같다. 이 사상에서 나온 보정법이 라플라스 추정기(Laplace estimator)이며, Outlook 에서 play=no인 경우 확률을 보정한다. (0인 값을 없앤다). No인 경우 분모에 보정값 3을 더하고 분자에 보정값/3 = 1 을 더하여 보정하면
| Yes | No | |
|---|---|---|
| Sunny | 2/9 | (2+1)/(5+3) = 3/8 |
| Overcast | 4/9 | (0+1)/(5+3) = 1/8 |
| rainly | 3/9 | (3+1)/(5+3) = 4/8 |
이 경우는 보정값이 3인 경우였지만 상황에 따라 보정값이 3이 아닌 경우도 있다. 보정값을 μ라고 하면 아래와 같이 될 것이다.
이후 구하는 방법은 앞과 동일하다. 이를 나이브 베이지안(Naïve Bayesian) + 라플라스 추정기 방법이라고 한다.
-
이 방법의 조건은 각 팩터들이 독립적이며 서로 영향을 미치지 않는다는 전제 조건이 있다. 가중치 등이 필요한 경우는 다른 방법이 필요하다. ↩